基于Risc的Chinite
栏目:成功案例 发布时间:2025-07-21 12:54
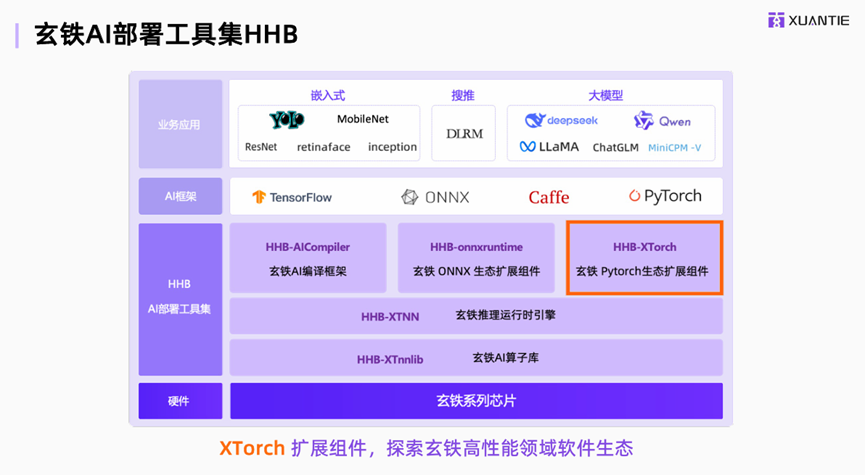 7月18日,第5届RISC-V峰会中国参加了上海的一项副校园会议。作为未来电子行业最大的应用领域之一,人工智能是不可避免的主题。人工智能的快速发展促进了基本建筑的创新,这是计算机能源需求的平均年增长率超过100%。 RISC-V“开放,灵活和可定制”是建立独立计算机功率基石的战略支持点。人工智能子宫邀请所有有关方面讨论RISC-V体系结构如何利用开源功能,开放且可扩展的功能,以允许AI计算机架构中的创新以及如何在AI软件和硬件中实现RISC-V Architectures应用程序的最新进展和实现。阿里巴巴Damo学院的工程师高级发展Xu Peng分享了其大型模型部署和优化实践Xuantie AI的CES在游行中。作为中国高性能IP RISC-V处理器开发的先驱,Xuantien团队一直是AI应用程序实施技术的RISC-V国家体系结构的边界。 Xu Peng介绍了2025年3月底,“ Maopa社区”的开源数量超过52,000,同时“ Qianwen Model Family”数字及其派生模型超过100,000。传统模型的数量不仅很大,而且在各种行业和行业中都出现了大型模型。 Xuantie正在积极促进向量和AME的进步。目前,当前的RISC-V社区向量已准备就绪,AME也正在快速移动。根据以前的商业需求和更新,已经提出了对上部软件电池的更高要求。特别是由于Xuantien处理器能力的发展,Xuantien开始执行矢量2019年为0.7.1,其次是向量1.0,随后是一个出色的Pytor Ancholas CH和AME单元。最近,Xuantien更新了其第二代AME单元。 Xuantie Hardware继续发展其Pytorch和AME加速单元,提高计算机功率,补充数据类型支持,加速的特殊操作能力以及对LLM方案的特定改进。下图说明了与Xuantie,Xuantie AI部署工具集HH相关的商业和硬件需求的生态系统。 Xuantie AI工具集包括三个级别,包括HHB AICompiler,HHB -OXRUNTIME和HHB -XTORCH。 Xuantie的另一个重要任务是Pytorch的扩展。为了提供足够的支持支持Pytorch,用户可以在RISC-V硬件上不痛苦而改变,而另一方面,重复使用Pytorch当前成熟的成熟软件生态系统并扩展了RISC-V的功能。尤其是使用Xtorch,Xtorch提供了一组大型和MOE模式的合并LS运营商,终端绩效的终点提高了11.2%。同时,在此级别上实现用户非常方便,为大型模型提供了出色的传统算法。例如,AWQ,GPTQ等。它们还提供了多裂量量化功能和多次接收功能,例如Q80。让我们看看Xtorch如何加速大型模型的推理。以下图用作典型图。 Ormer的范式推断大型模型。在最简单的过程中,您必须插入两行代码,以允许Xtorch在右侧实现Pytorch加速度的Morenative,XTORCH中有一些任务,例如Moe Fusion Operator,以及其他对合并和操作员模型的传统优化。工作中的第三个进展是黑铁执行时间引擎和黑铁操作员库。 Xuan Iron NN库承认静态和动态图形的推断D当前是一个很棒的模型,可以接受多种数据类型的定量推断,例如FP8和FP4,以及必须使用的新数据类型。当计算机任务进入Xuantien的NN操作时,整个计算机任务将分为运算符的任务,以在背景中执行适当的操作。 Xuantien在线程之间提供负载平衡,并形成多个内核的最佳推理。同时,在大型推理过程中,Xuan Tie将单个GR模型计算任务和计算机流量视为相同的计算机流,然后通过对所有计算机流的全局分析,最大程度地将执行硬件的并行能力最大化,并且图形的推断将末端-TO -TO -TO -TO -TO -TO -END收益率提高了20.5%。传输数据单元中的基础图层抽象矩阵和向量,同时放置所有计算和通信任务,从而减少了传统执行方法的硬件延迟。领带XUAN设备的优势是它可以执行协调的软件和硬件优化,并使用并行功能加速软件计算。该硬件被分析为需求,最终构成了DUP系列减少系列的指令,并最终构成了SoftMax,随着闭环的加速,SoftMax的增加了8倍。从矢量的角度来看,大型模型中使用的编码使用Sigmoid操作,并且没有最小黑色硬件的最小值可以加速功能。例如,Sigmoid和Sil操作员的表现要好得多五倍。与FP16及其竞争对手相比,加速效应高约三倍。
7月18日,第5届RISC-V峰会中国参加了上海的一项副校园会议。作为未来电子行业最大的应用领域之一,人工智能是不可避免的主题。人工智能的快速发展促进了基本建筑的创新,这是计算机能源需求的平均年增长率超过100%。 RISC-V“开放,灵活和可定制”是建立独立计算机功率基石的战略支持点。人工智能子宫邀请所有有关方面讨论RISC-V体系结构如何利用开源功能,开放且可扩展的功能,以允许AI计算机架构中的创新以及如何在AI软件和硬件中实现RISC-V Architectures应用程序的最新进展和实现。阿里巴巴Damo学院的工程师高级发展Xu Peng分享了其大型模型部署和优化实践Xuantie AI的CES在游行中。作为中国高性能IP RISC-V处理器开发的先驱,Xuantien团队一直是AI应用程序实施技术的RISC-V国家体系结构的边界。 Xu Peng介绍了2025年3月底,“ Maopa社区”的开源数量超过52,000,同时“ Qianwen Model Family”数字及其派生模型超过100,000。传统模型的数量不仅很大,而且在各种行业和行业中都出现了大型模型。 Xuantie正在积极促进向量和AME的进步。目前,当前的RISC-V社区向量已准备就绪,AME也正在快速移动。根据以前的商业需求和更新,已经提出了对上部软件电池的更高要求。特别是由于Xuantien处理器能力的发展,Xuantien开始执行矢量2019年为0.7.1,其次是向量1.0,随后是一个出色的Pytor Ancholas CH和AME单元。最近,Xuantien更新了其第二代AME单元。 Xuantie Hardware继续发展其Pytorch和AME加速单元,提高计算机功率,补充数据类型支持,加速的特殊操作能力以及对LLM方案的特定改进。下图说明了与Xuantie,Xuantie AI部署工具集HH相关的商业和硬件需求的生态系统。 Xuantie AI工具集包括三个级别,包括HHB AICompiler,HHB -OXRUNTIME和HHB -XTORCH。 Xuantie的另一个重要任务是Pytorch的扩展。为了提供足够的支持支持Pytorch,用户可以在RISC-V硬件上不痛苦而改变,而另一方面,重复使用Pytorch当前成熟的成熟软件生态系统并扩展了RISC-V的功能。尤其是使用Xtorch,Xtorch提供了一组大型和MOE模式的合并LS运营商,终端绩效的终点提高了11.2%。同时,在此级别上实现用户非常方便,为大型模型提供了出色的传统算法。例如,AWQ,GPTQ等。它们还提供了多裂量量化功能和多次接收功能,例如Q80。让我们看看Xtorch如何加速大型模型的推理。以下图用作典型图。 Ormer的范式推断大型模型。在最简单的过程中,您必须插入两行代码,以允许Xtorch在右侧实现Pytorch加速度的Morenative,XTORCH中有一些任务,例如Moe Fusion Operator,以及其他对合并和操作员模型的传统优化。工作中的第三个进展是黑铁执行时间引擎和黑铁操作员库。 Xuan Iron NN库承认静态和动态图形的推断D当前是一个很棒的模型,可以接受多种数据类型的定量推断,例如FP8和FP4,以及必须使用的新数据类型。当计算机任务进入Xuantien的NN操作时,整个计算机任务将分为运算符的任务,以在背景中执行适当的操作。 Xuantien在线程之间提供负载平衡,并形成多个内核的最佳推理。同时,在大型推理过程中,Xuan Tie将单个GR模型计算任务和计算机流量视为相同的计算机流,然后通过对所有计算机流的全局分析,最大程度地将执行硬件的并行能力最大化,并且图形的推断将末端-TO -TO -TO -TO -TO -TO -END收益率提高了20.5%。传输数据单元中的基础图层抽象矩阵和向量,同时放置所有计算和通信任务,从而减少了传统执行方法的硬件延迟。领带XUAN设备的优势是它可以执行协调的软件和硬件优化,并使用并行功能加速软件计算。该硬件被分析为需求,最终构成了DUP系列减少系列的指令,并最终构成了SoftMax,随着闭环的加速,SoftMax的增加了8倍。从矢量的角度来看,大型模型中使用的编码使用Sigmoid操作,并且没有最小黑色硬件的最小值可以加速功能。例如,Sigmoid和Sil操作员的表现要好得多五倍。与FP16及其竞争对手相比,加速效应高约三倍。